Nowdays , i hava a task about how to use shell script ,so it is time to learn shell .
shell 入门
好用的工具网站
# ALL
https://www.runoob.com/linux/linux-command-manual.html
# zip 和 upzip
1 | # zip命令的选项说明 |
1 | # 解压到当前目录 如果文件已存在,会提示是否替换,可以使用 -o 或 -n 参数简化交互; |
# Bash shell 脚本打印出正在执行的命令
1 | # 默认情况下,bash脚本不会打印执行的每个命令,这个有时候不太方面。 |
# sed 指令
参考地址
sed 命令的基本格式如下: sed [选项] [脚本命令] 文件名
该命令常用的选项及含义:
| 选项 | 含义 |
|---|---|
-e |
脚本命令 该选项会将其后跟的脚本命令添加到已有的命令中。 |
-f |
脚本命令文件 该选项会将其后文件中的脚本命令添加到已有的命令中。 |
-n |
默认情况下, sed 会在所有的脚本指定执行完毕后,会自动输出处理后的内容,而该选项会屏蔽启动输出,需使用 print 命令来完成输出。 |
-i |
此选项会直接修改源文件,要慎用。 |
# sed s 替换脚本命令
此命令的基本格式为:
1 | # 其中,address 表示指定要操作的具体行,pattern 指的是需要替换的内容,replacement 指的是要替换的新内容。 |
其中 flag :
flags 标记 |
功能 |
|---|---|
n |
1~512 之间的数字,表示指定要替换的字符串出现第几次时才进行替换,例如,一行中有 3 个 A ,但用户只想替换第二个 A ,这是就用到这个标记; |
g |
对数据中所有匹配到的内容进行替换,如果没有 g ,则只会在第一次匹配成功时做替换操作。例如,一行数据中有 3 个 A ,则只会替换第一个 A ; |
p |
会打印与替换命令中指定的模式匹配的行。此标记通常与 -n 选项一起使用。 |
w file |
将缓冲区中的内容写到指定的 file 文件中; |
& |
用正则表达式匹配的内容进行替换; |
\n |
匹配第 n 个子串,该子串之前在 pattern 中用 () 指定。 |
\ |
转义(转义替换部分包含: &、\ 等)。 |
tips– 需要转义的一些字符:

-
比如,可以指定
sed用新文本替换第几处模式匹配的地方:1
2
3$sed 's/test/trial/2' data4.txt
This is a test of the trial script.
This is the second test of the trial script.可以看到,使用数字
2作为标记的结果就是,sed编辑器只替换每行中第2次出现的匹配模式。 -
如果要用新文件替换所有匹配的字符串,可以使用
g标记:1
2
3$sed 's/test/trial/g' data4.txt
This is a trial of the trial script.
This is the second trial of the trial script. -
我们知道,
-n选项会禁止sed输出,但p标记会输出修改过的行,将二者匹配使用的效果就是只输出被替换命令修改过的行,例如:1
2
3
4
5$cat data5.txt
This is a test line.
This is a different line.
$sed -n 's/test/trial/p' data5.txt
This is a trial line. -
w标记会将匹配后的结果保存到指定文件中,比如:1
2
3
4
5$sed 's/test/trial/w test.txt' data5.txt
This is a trial line.
This is a different line.
$#cat test.txt
This is a trial line. -
在使用
s脚本命令时,替换类似文件路径的字符串会比较麻烦,需要将路径中的正斜线进行转义,例如:1
sed 's/\/bin\/bash/\/bin\/csh/' /etc/passwd
# sed d 替换脚本命令
此命令的基本格式为: [address]d
如果需要删除文本中的特定行,可以用 d 脚本命令,它会删除指定行中的所有内容。但使用该命令时要特别小心,如果你忘记指定具体行的话,文件中的所有内容都会被删除,举个例子:
1 | $cat data1.txt |
-
通过行号指定,比如删除
data6.txt文件内容中的第3行:1
2
3
4
5
6
7
8
9$cat data6.txt
This is line number 1.
This is line number 2.
This is line number 3.
This is line number 4.
$sed '3d' data6.txt
This is line number 1.
This is line number 2.
This is line number 4. -
或者通过特定行区间指定,比如删除
data6.txt文件内容中的第2、3行:1
2
3$sed '2,3d' data6.txt
This is line number 1.
This is line number 4. -
也可以使用两个文本模式来删除某个区间内的行,但这么做时要小心,你指定的第一个模式会 “打开” 行删除功能,第二个模式会 “关闭” 行删除功能,因此,
sed会删除两个指定行之间的所有行(包括指定的行),例如:1
2
3$sed '/1/,/3/d' data6.txt
#删除第 1~3 行的文本数据
This is line number 4. -
或者通过特殊的文件结尾字符,比如删除
data6.txt文件内容中第3行开始的所有的内容:1
2
3$sed '3,$d' data6.txt
This is line number 1.
This is line number 2.
在此强调,在默认情况下 sed 并不会修改原始文件,这里被删除的行只是从 sed 的输出中消失了,原始文件没做任何改变。
完整版参考地址
# Grep 指令
菜鸟链接
# awk 指令
菜鸟链接
good 1
# cut 指令
菜鸟链接
三剑客链接
# JSON 格式化工具 jq 指令
参考链接
# awk 内置函数 (split/substr/length/gsub)
一、 split 初始化和类型强制
awk 的内建函数 split 允许你把一个字符串分隔为单词并存储在数组中。你可以自己定义域分隔符或者使用现在 FS(域分隔符) 的值。
格式:
1 | split (string, array, field separator) |
例子:
1 |
|
计算指定范围内的和 (计算每个人 1 月份的工资之和):
1 | # test.txt: |
二、 substr 截取字符串
返回从起始位置起,指定长度之子字符串;若未指定长度,则返回从起始位置到字符串末尾的子字符串。
格式:
1 | substr(s,p) 返回字符串s中从p开始的后缀部分 |
例子:
1 | echo "abc" | awk '{print substr($0,2,2)}' |
三、 length 字符串长度
length 函数返回没有参数的字符串的长度。 length 函数返回整个记录中的字符数。
1 | echo "abc" | awk '{print length}' |
四、 gsub 函数
gsub 函数则使得在所有正则表达式被匹配的时候都发生替换。 gsub(regular expression, subsitution string, target string);简称 gsub(r,s,t) 。
举例:把一个文件里面所有包含 abc 的行里面的 abc 替换成 def ,然后输出第一列和第三列
1 | echo "abc cde abr" | awk '$0 ~ /abc/ {gsub("abc","def",$0); print $1, $3}' |
# Linux shell 将字符串分割成数组
1 | a="one,two,three,four" |
# linux 截取中间字符串, shell 截取指定字符串之间的内容
1 |
|
# Shell 环境生成 UUID
1 | UUID=$(uuidgen |sed 's/-//g') |
# Shell 中 $ 各种含义
| 符 号 | 含 义 |
|---|---|
$0 |
脚本名 |
$# |
参数个数 |
$n |
传递给脚本的参数值, $1 第 1 参数、 $2 第 2 参数 |
$? |
上次退出的状态(返回值), 0 没有错误, 1 错误 |
$* |
所有参数列表。 "$*" 时,是 "$1 $2 … $n" 的形式 |
$@ |
所有参数列表。 "$@" 时,是 "$1" "$2" … "$n" 的形式 |
$$ |
当前进程的编号 (ProcessID) |
$! |
shell 最后运行的后台 Process 的 PID |
$var |
变量,会与后面的连接,如 $var_a ,会当做变量 var_a |
${var} |
变量,界定范围 |
$() |
与 (反引号)类似,里面执行完再返回值, 所有 shell 通用 |
$[] |
可进行算术运算和逻辑运算,不支持浮点和字符串 |
$(()) |
可进行算术运算和逻辑运算,不支持浮点和字符串。里面的变量可以省略 $ |
# linux 下 shell 中 if 的 “-e,-d,-f” 是什么意思
1 | 文件表达式 |
# shell 获取文件扩展名
1 | basename example.tar.a.b.c.gz .c.gz |
# Linux shell 中获取当前目录的方法
当前目录
每当你在终端进行操作时,你都会有一个当前工作目录。 使用 pwd 来判定当前目录在文件系统内的确切位置。
1 | $pwd |
在 shell 中也可以使用 pwd 来获取当前目录,并赋值给变量。
1 |
|
工作目录
获取当前执行的脚本文件的父目录。
1 | workdir=$(cd $(dirname $0); pwd) |
复杂点的工作目录获取
1 | PRG="$0" |
# Linux Shell 获取文件夹下的文件名
1 |
|
# shell 获取目录下所有文件夹的名称并输出
1 |
|
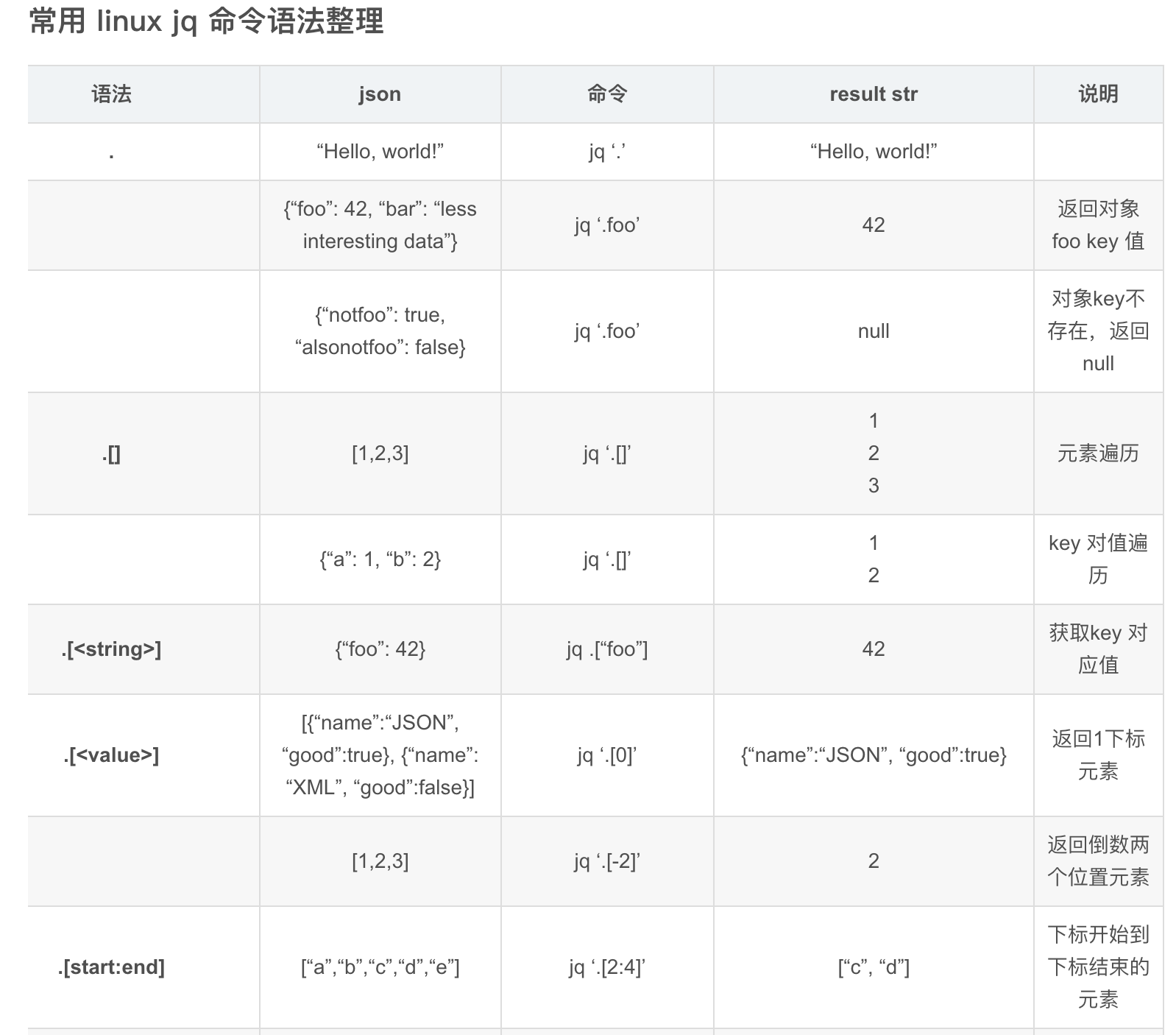
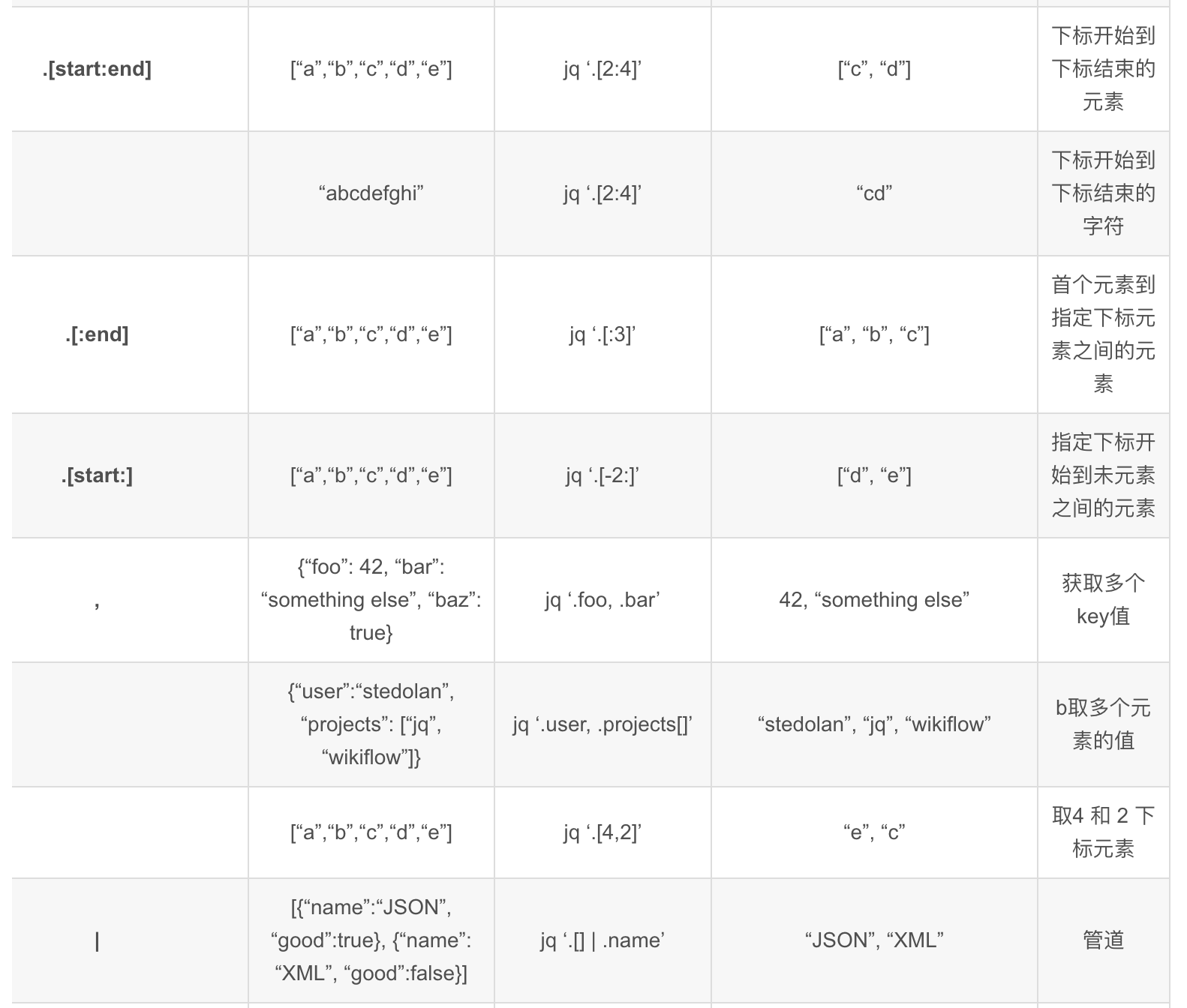
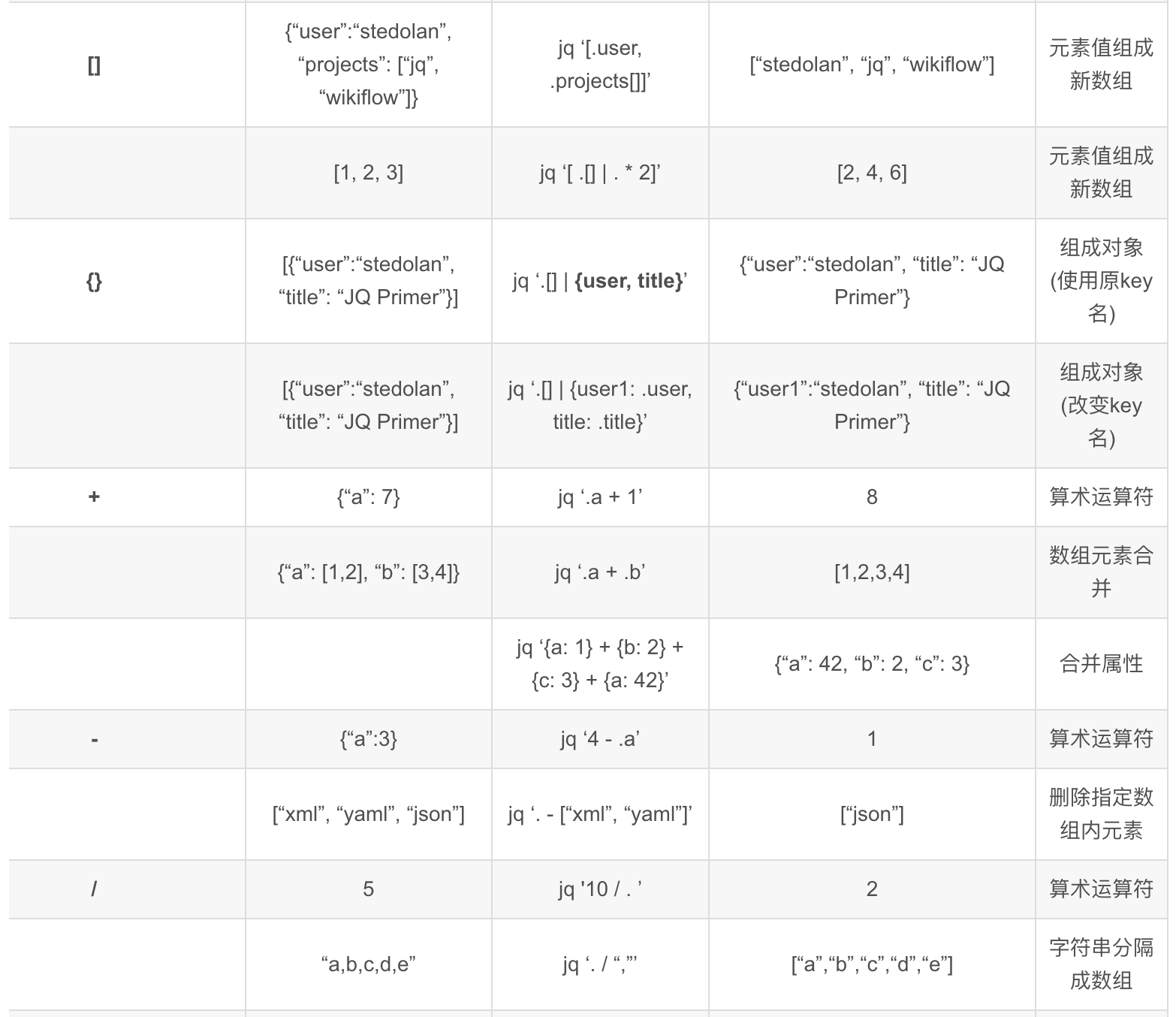
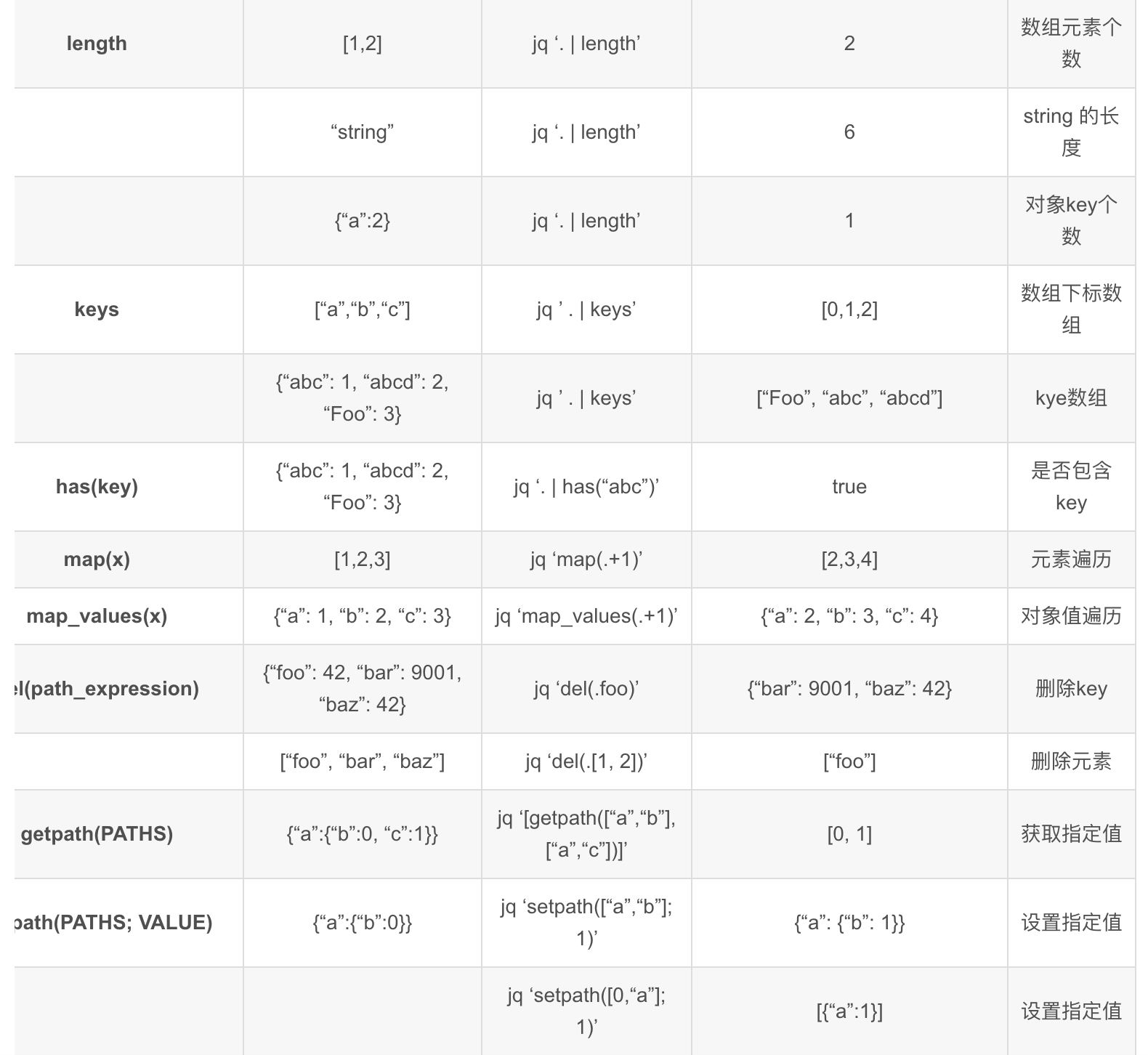
# 常用 Linux jq 命令语法整理
参考链接
# shell 脚本中整数型变量自增(加 1 )的实现方式
1 | !/bin/sh |
# shell 判断一个变量是否为空
1 | [ ! $a ] && echo "a is null" |
# 输出到文件
1 | 两种方法: |
# Shell 实现多线程(多任务)
- 命令结尾添加:
& - 解决主线程提前退出问题,添加
wait - 控制后台执行数(线程数),
mkfifo
https://www.cnblogs.com/zhengbin/p/9513762.html