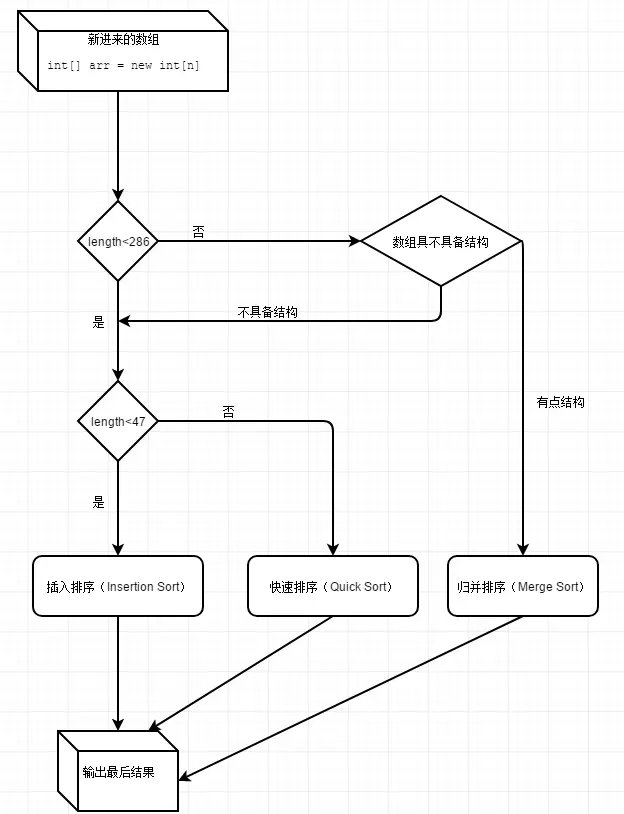
/** 如果可能合并,使用给定的工作空间数组片对数组的指定范围进行排序 参数: a -要排序的数组 left - 要排序的第一个元素的索引(包括第一个元素) right - 最后一个要排序的元素的下标 Work -工作空间数组(片) workBase -工作数组中可用空间的来源 workLen -工作数组的可用大小 */
staticvoidsort(int[] a, int left, int right,int[] work, int workBase, int workLen){ // 小数组使用快排,阈值为286 if (right - left < QUICKSORT_THRESHOLD) { //快排 sort(a, left, right, true); return; }
//索引运行[i]是第i次运行的开始(升序或降序)。 int[] run = newint[MAX_RUN_COUNT + 1]; int count = 0; run[0] = left;
// 检查数组是否接近排序 见解释 1 for (int k = left; k < right; run[count] = k) { // 序列开头相等的项 while (k < right && a[k] == a[k + 1]) k++; if (k == right) break; // 序列以相等的项结束 if (a[k] < a[k + 1]) { // 升序 while (++k <= right && a[k - 1] <= a[k]); } elseif (a[k] > a[k + 1]) { // 降序 while (++k <= right && a[k - 1] >= a[k]); //转换成一个升序序列 for (int lo = run[count] - 1, hi = k; ++lo < --hi; ) { int t = a[lo]; a[lo] = a[hi]; a[hi] = t; } }
// 合并一个转换后的降序序列,后面跟着升序序列 if (run[count] > left && a[run[count]] >= a[run[count] - 1]) { count--; }
// 确定合并的交替基 byte odd = 0; for (int n = 1; (n <<= 1) < count; odd ^= 1);
// 使用或创建临时数组b进行合并 int[] b; // temp array; alternates with a int ao, bo; // array offsets from 'left' int blen = right - left; // space needed for b if (work == null || workLen < blen || workBase + blen > work.length) { work = newint[blen]; workBase = 0; } if (odd == 0) { System.arraycopy(a, left, work, workBase, blen); b = a; bo = 0; a = work; ao = workBase - left; } else { b = work; ao = 0; bo = workBase - left; }
// 归并 for (int last; count > 1; count = last) { for (int k = (last = 0) + 2; k <= count; k += 2) { int hi = run[k], mi = run[k - 1]; for (int i = run[k - 2], p = i, q = mi; i < hi; ++i) { if (q >= hi || p < mi && a[p + ao] <= a[q + ao]) { b[i + bo] = a[p++ + ao]; } else { b[i + bo] = a[q++ + ao]; } } run[++last] = hi; } if ((count & 1) != 0) { for (int i = right, lo = run[count - 1]; --i >= lo; b[i + bo] = a[i + ao] ); run[++last] = right; } int[] t = a; a = b; b = t; int o = ao; ao = bo; bo = o; } }
/** * 按双重Povit快速排序 对数组的指定范围进行排序 * * @param a 待排序数组 * @param left 待排数组左索引 * @param right 待排数组右索引 * @param leftmost 指示这部分是否为范围的最左边 */ privatestaticvoidsort(int[] a, int left, int right, boolean leftmost){ int length = right - left + 1;
// 小于47,使用插入排序 if (length < INSERTION_SORT_THRESHOLD) { if (leftmost) { //传统的(没有哨兵的)插入排序,为服务器虚拟机优化,用于最左边的部分。 for (int i = left, j = i; i < right; j = ++i) { int ai = a[i + 1]; while (ai < a[j]) { a[j + 1] = a[j]; if (j-- == left) { break; } } a[j + 1] = ai; } } else { //跳过最长升序序列。 do { if (left >= right) { return; } } while (a[++left] >= a[left - 1]);
//来自相邻部分的每一个元素都起着作用,因此这允许我们避免每次迭代的左范围检查。 //此外,我们使用更优化的算法,所谓的对插入排序,它更快(在快速排序的上下文中)比传统的插入排序实现。 for (int k = left; ++left <= right; k = ++left) { int a1 = a[k], a2 = a[left];
// 对五个均匀间隔的元素进行排序 ,在范围的中心元素。这些元素将被用于枢轴选择如下所述。 //间隔的选择 根据经验,这些因素决定很好地发挥作用 各种各样的输入。 int e3 = (left + right) >>> 1; // The midpoint int e2 = e3 - seventh; int e1 = e2 - seventh; int e4 = e3 + seventh; int e5 = e4 + seventh;
// 使用插入排序对这些元素进行排序 if (a[e2] < a[e1]) { int t = a[e2]; a[e2] = a[e1]; a[e1] = t; }
if (a[e3] < a[e2]) { int t = a[e3]; a[e3] = a[e2]; a[e2] = t; if (t < a[e1]) { a[e2] = a[e1]; a[e1] = t; } } if (a[e4] < a[e3]) { int t = a[e4]; a[e4] = a[e3]; a[e3] = t; if (t < a[e2]) { a[e3] = a[e2]; a[e2] = t; if (t < a[e1]) { a[e2] = a[e1]; a[e1] = t; } } } if (a[e5] < a[e4]) { int t = a[e5]; a[e5] = a[e4]; a[e4] = t; if (t < a[e3]) { a[e4] = a[e3]; a[e3] = t; if (t < a[e2]) { a[e3] = a[e2]; a[e2] = t; if (t < a[e1]) { a[e2] = a[e1]; a[e1] = t; } } } }
// Pointers int less = left; // The index of the first element of center part int great = right; // The index before the first element of right part
if (a[e1] != a[e2] && a[e2] != a[e3] && a[e3] != a[e4] && a[e4] != a[e5]) { //使用五个排序元素中的第二个和第四个作为枢轴。 //这些值是第一个和的廉价近似值. Note that pivot1 <= pivot2. int pivot1 = a[e2]; int pivot2 = a[e4];
/* * The first and the last elements to be sorted are moved to the * locations formerly occupied by the pivots. When partitioning * is complete, the pivots are swapped back into their final * positions, and excluded from subsequent sorting. */ a[e2] = a[left]; a[e4] = a[right];
/* * Skip elements, which are less or greater than pivot values. */ while (a[++less] < pivot1); while (a[--great] > pivot2);
/* * Partitioning: * * left part center part right part * +--------------------------------------------------------------+ * | < pivot1 | pivot1 <= && <= pivot2 | ? | > pivot2 | * +--------------------------------------------------------------+ * ^ ^ ^ * | | | * less k great * * Invariants: * * all in (left, less) < pivot1 * pivot1 <= all in [less, k) <= pivot2 * all in (great, right) > pivot2 * * Pointer k is the first index of ?-part. */ outer: for (int k = less - 1; ++k <= great; ) { int ak = a[k]; if (ak < pivot1) { // Move a[k] to left part a[k] = a[less]; /* * Here and below we use "a[i] = b; i++;" instead * of "a[i++] = b;" due to performance issue. */ a[less] = ak; ++less; } elseif (ak > pivot2) { // Move a[k] to right part while (a[great] > pivot2) { if (great-- == k) { break outer; } } if (a[great] < pivot1) { // a[great] <= pivot2 a[k] = a[less]; a[less] = a[great]; ++less; } else { // pivot1 <= a[great] <= pivot2 a[k] = a[great]; } /* * Here and below we use "a[i] = b; i--;" instead * of "a[i--] = b;" due to performance issue. */ a[great] = ak; --great; } }
// Swap pivots into their final positions a[left] = a[less - 1]; a[less - 1] = pivot1; a[right] = a[great + 1]; a[great + 1] = pivot2;
// Sort left and right parts recursively, excluding known pivots sort(a, left, less - 2, leftmost); sort(a, great + 2, right, false);
/* * If center part is too large (comprises > 4/7 of the array), * swap internal pivot values to ends. */ if (less < e1 && e5 < great) { /* * Skip elements, which are equal to pivot values. */ while (a[less] == pivot1) { ++less; }
while (a[great] == pivot2) { --great; }
/* * Partitioning: * * left part center part right part * +----------------------------------------------------------+ * | == pivot1 | pivot1 < && < pivot2 | ? | == pivot2 | * +----------------------------------------------------------+ * ^ ^ ^ * | | | * less k great * * Invariants: * * all in (*, less) == pivot1 * pivot1 < all in [less, k) < pivot2 * all in (great, *) == pivot2 * * Pointer k is the first index of ?-part. */ outer: for (int k = less - 1; ++k <= great; ) { int ak = a[k]; if (ak == pivot1) { // Move a[k] to left part a[k] = a[less]; a[less] = ak; ++less; } elseif (ak == pivot2) { // Move a[k] to right part while (a[great] == pivot2) { if (great-- == k) { break outer; } } if (a[great] == pivot1) { // a[great] < pivot2 a[k] = a[less]; /* * Even though a[great] equals to pivot1, the * assignment a[less] = pivot1 may be incorrect, * if a[great] and pivot1 are floating-point zeros * of different signs. Therefore in float and * double sorting methods we have to use more * accurate assignment a[less] = a[great]. */ a[less] = pivot1; ++less; } else { // pivot1 < a[great] < pivot2 a[k] = a[great]; } a[great] = ak; --great; } } }
// 对中心部分进行递归排序 sort(a, less, great, false);
} else { // Partitioning with one pivot /* * Use the third of the five sorted elements as pivot. * This value is inexpensive approximation of the median. */ int pivot = a[e3];
/* * Partitioning degenerates to the traditional 3-way * (or "Dutch National Flag") schema: * * left part center part right part * +-------------------------------------------------+ * | < pivot | == pivot | ? | > pivot | * +-------------------------------------------------+ * ^ ^ ^ * | | | * less k great * * Invariants: * * all in (left, less) < pivot * all in [less, k) == pivot * all in (great, right) > pivot * * Pointer k is the first index of ?-part. */ for (int k = less; k <= great; ++k) { if (a[k] == pivot) { continue; } int ak = a[k]; if (ak < pivot) { // Move a[k] to left part a[k] = a[less]; a[less] = ak; ++less; } else { // a[k] > pivot - Move a[k] to right part while (a[great] > pivot) { --great; } if (a[great] < pivot) { // a[great] <= pivot a[k] = a[less]; a[less] = a[great]; ++less; } else { // a[great] == pivot /* * Even though a[great] equals to pivot, the * assignment a[k] = pivot may be incorrect, * if a[great] and pivot are floating-point * zeros of different signs. Therefore in float * and double sorting methods we have to use * more accurate assignment a[k] = a[great]. */ a[k] = pivot; } a[great] = ak; --great; } }
//对左右部分递归排序。所有元素从中心部分是相等的,因此,已经排序。 sort(a, left, less - 1, leftmost); sort(a, great + 1, right, false); } }